
Hugging Face 模型下载及使用


这篇文章介绍了Hugging Face平台和它的核心产品。演示了如何在AWS EC2实例上,从Hugging Face Hub下载并运行Qwen2-0.5B-Instruct模型。最后,还展示了如何用Gradio图形化界面与Qwen LLM进行聊天对话。
一、Hugging Face 简介
Hugging Face是一家美国公司,成立于2016年,起初是为青少年开发聊天机器人应用程序。后来,Hugging Face转型为专注于机器学习的平台公司,推出了多款促进NLP(自然语言处理)技术发展的产品。主要产品有:
- 预训练模型:Hugging Face提供了一系列优秀的预训练NLP模型,如BERT、GPT、RoBERTa等,这些模型在多项任务中表现出色。
- Transformers库:Hugging Face开发了名为
transformers的Python库,支持PyTorch和TensorFlow等深度学习框架,提供了加载、微调和使用预训练模型的便捷工具。 - NLP工具:他们提供了多种NLP相关工具,如文本生成、文本分类和命名实体识别,帮助开发者快速构建NLP应用。
- Hugging Face Hub:这是一个集中式的Web平台,类似于GitHub,托管基于Git的代码仓库、模型和数据集,并支持项目讨论和拉取请求。
- Hugging Face Spaces:Hugging Face Spaces是一个允许用户轻松部署和分享AI应用的平台。。它提供了一个易于使用的GUI,使用户能够快速创建和部署Web托管的ML应用。2021年底,Hugging Face宣布收购了Gradio。Gradio是一个开源Python包,允许用户快速为机器学习模型、API或任何Python函数构建交互式演示或Web应用程序,无需编写HTML、CSS或JavaScript代码。
二、大模型竞技场与排名
另外在Hugging Face可以查看各个大模型的排行榜,例如下面的开源大模型排行榜 [1]。
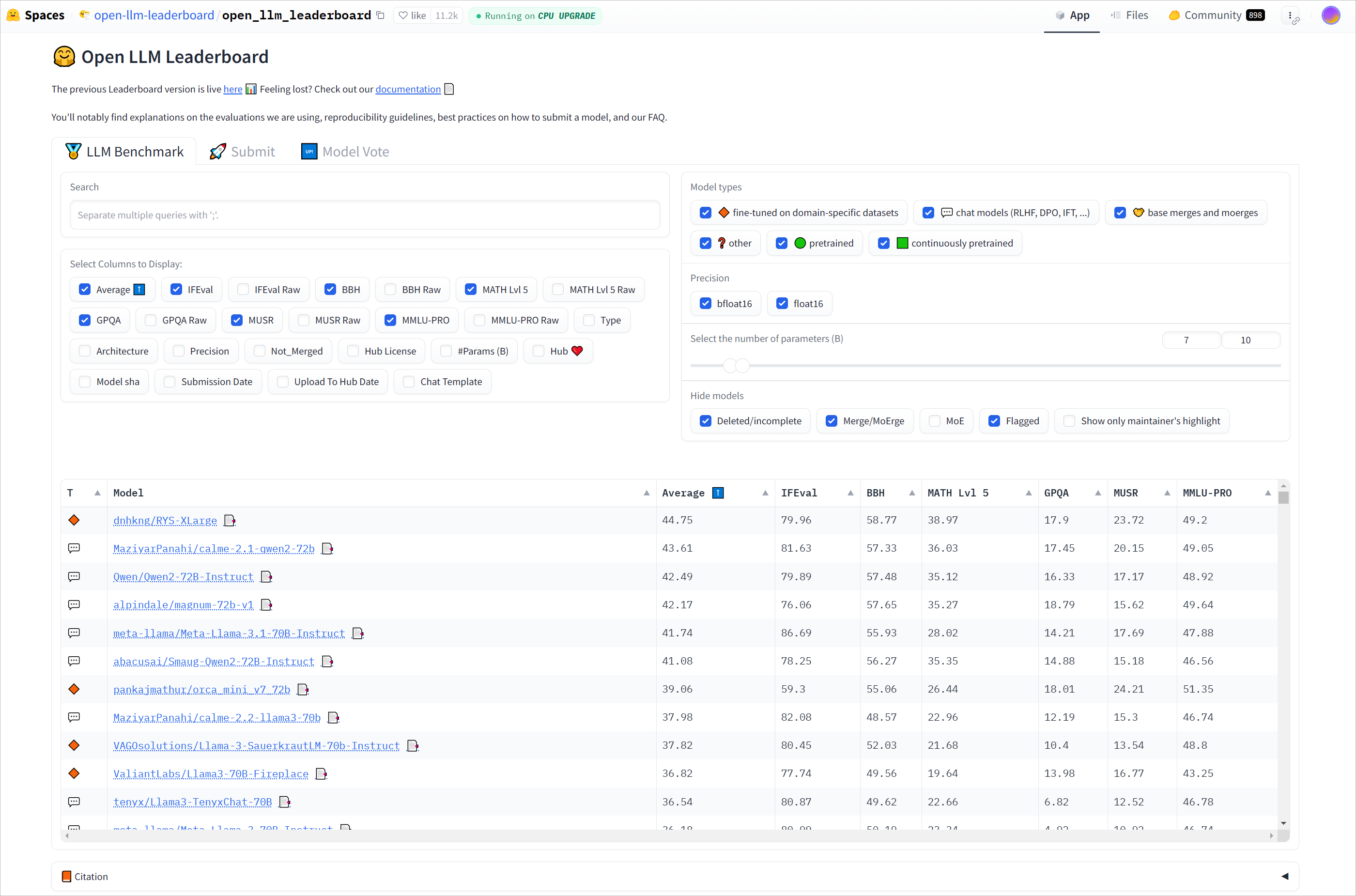
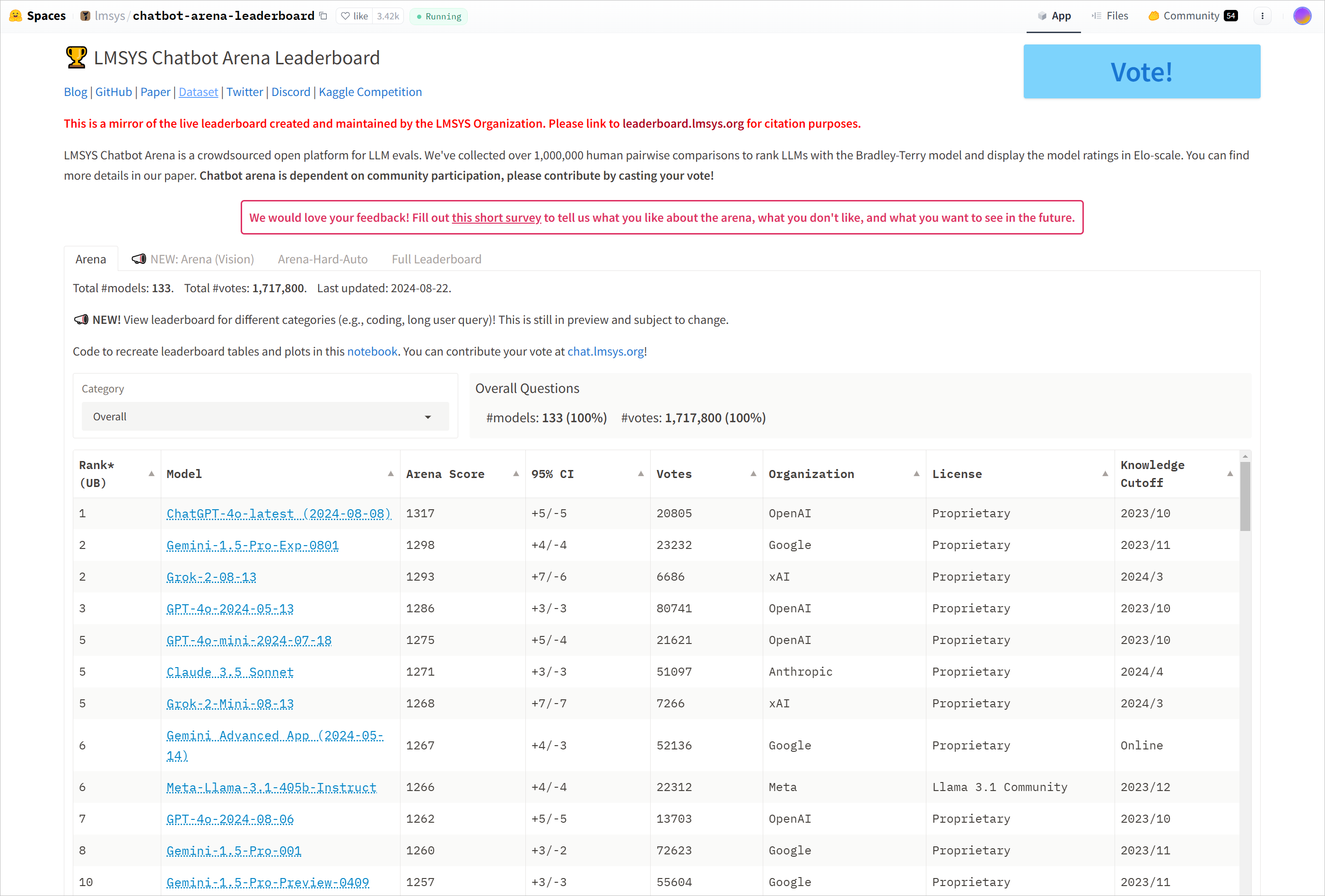
由LMSYS维护的大模型聊天竞技场,收集人类对大模型聊天回复的反馈,进行排名 [2]。
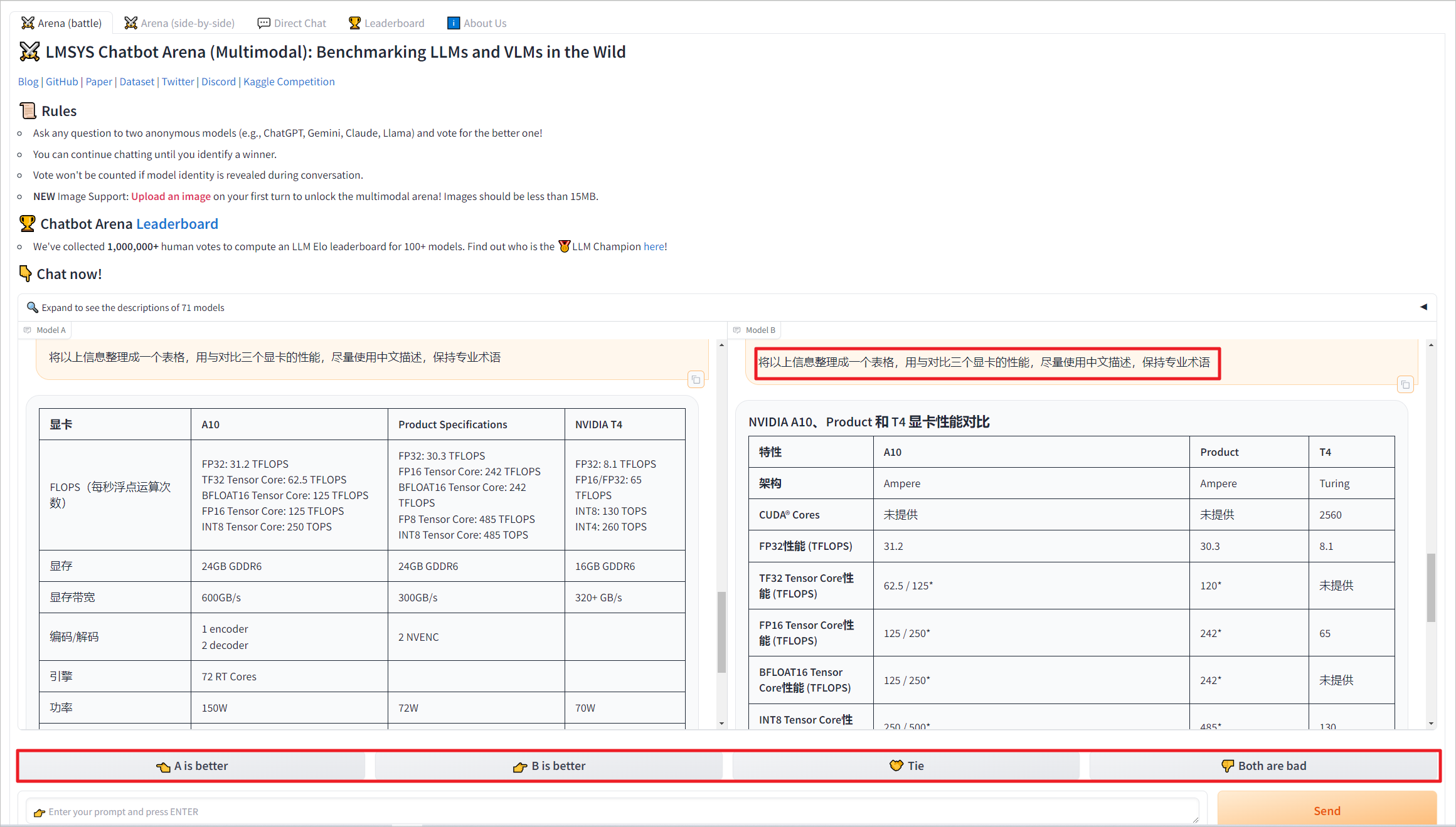
发送的问题会同时给两个模型进行回复,根据回复内容进行投票,一共4个选项,A胜、B胜、平手或者都不行。投票后会显示回复的大模型版本。
三、Hugging Face Spaces 使用
Hugging Face Spaces是一个允许用户轻松部署和分享AI应用的平台,很多大模型都会在Spaces上发布不同版本的模型,为大家提供测试。例如下面是Qwen的Spaces空间https://huggingface.co/Qwen [3]。
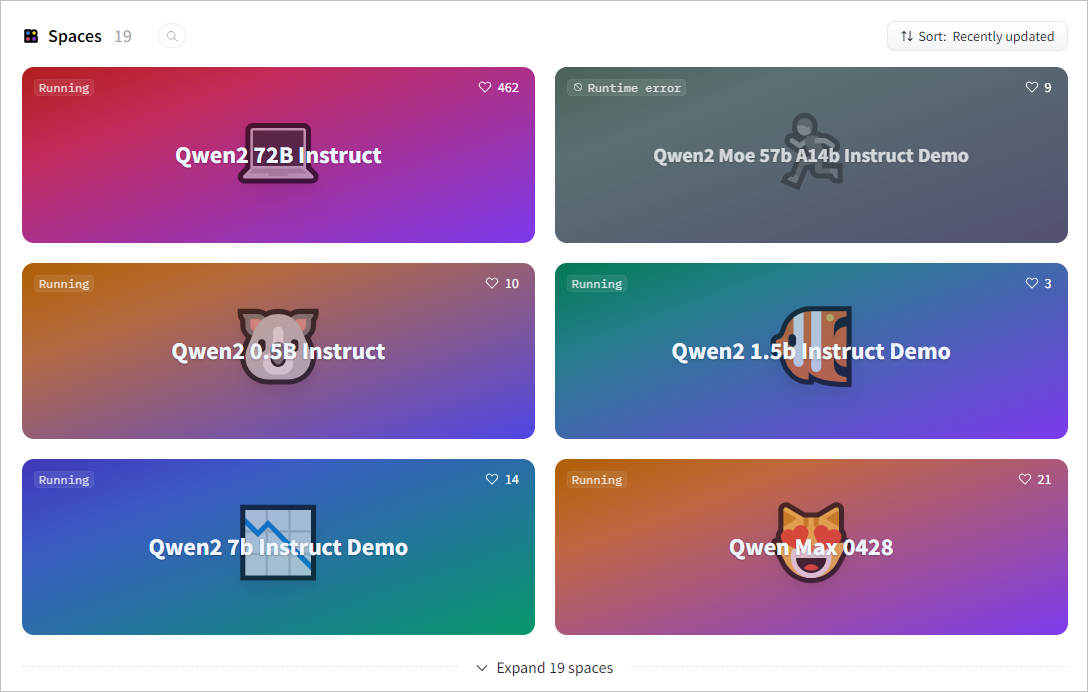
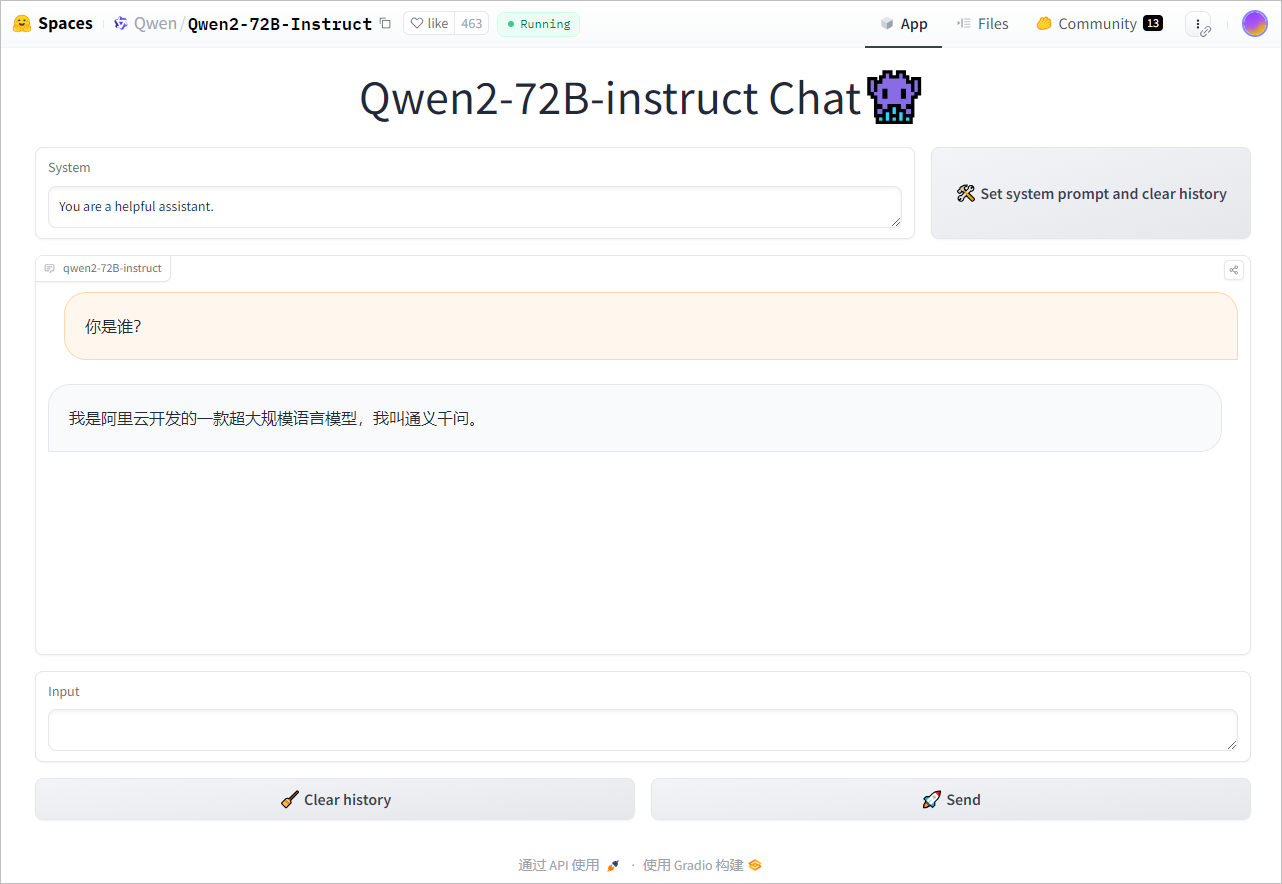
点击进入Qwen2-72B-Instruct Chat,可以进行聊天测试。
四、EC2 本地运行 Qwen2-0.5B-Instruct 模型
这部分演示一下,通过EC2下载和启动Qwen2-0.5B-Instruct模型。我选择Deep Learning类型的AMI,这个类型的AMI已经预先安装了英伟达的驱动。
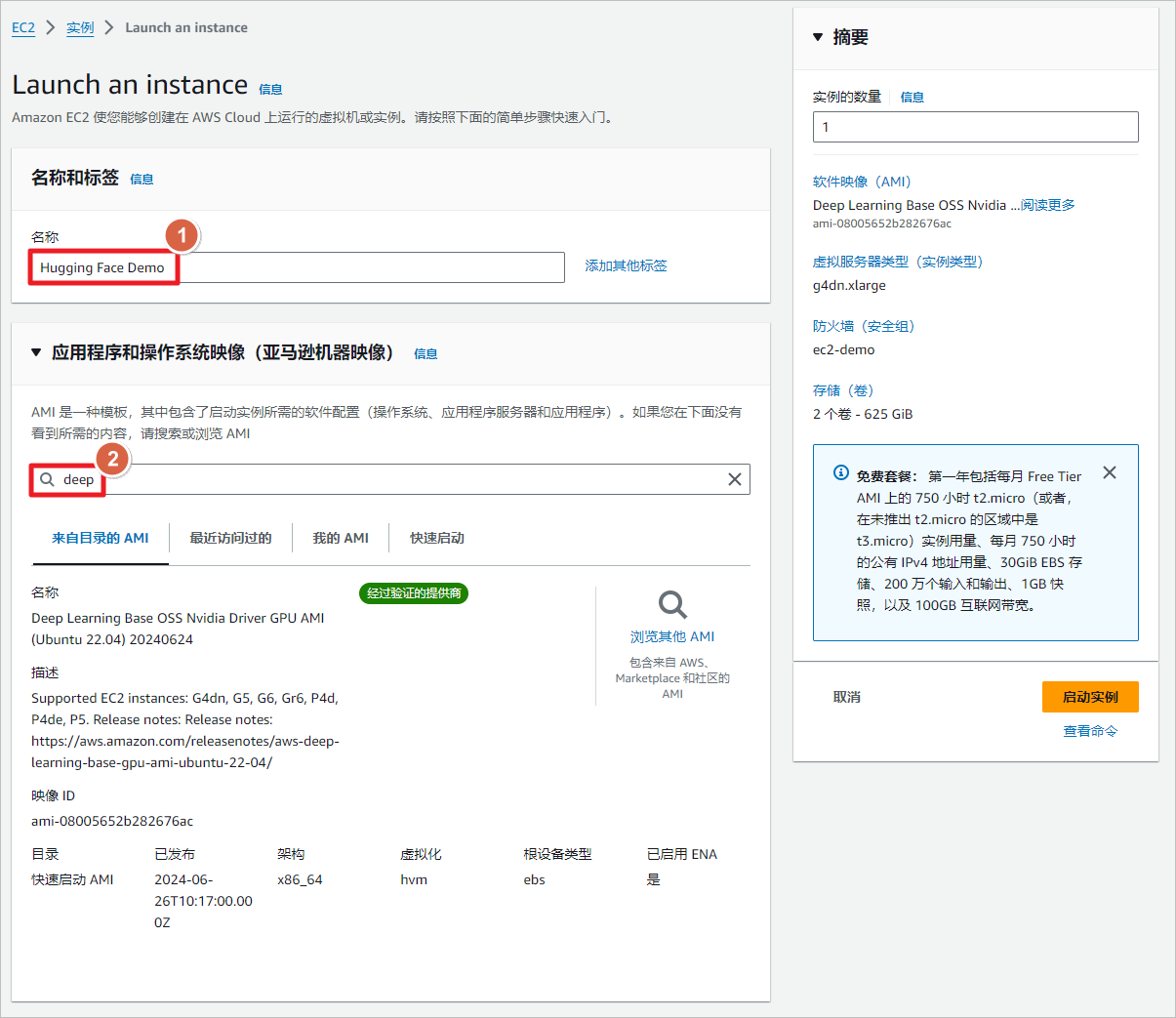
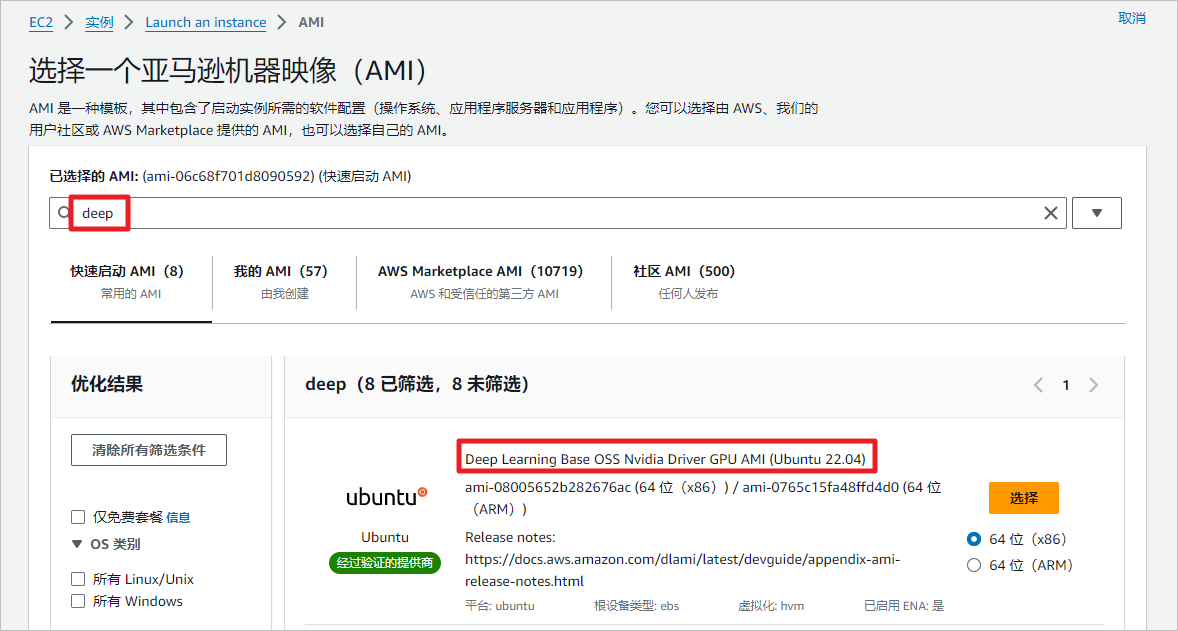
选择Ubuntu或者Amazon Linux2023都可以,这里我选择Ubuntu22.04版本的镜像。
选择g4dn.xlarge,带有1个NVIDA T4显卡,共有16GB GPU,这是带有英伟达显卡最便宜的实例。
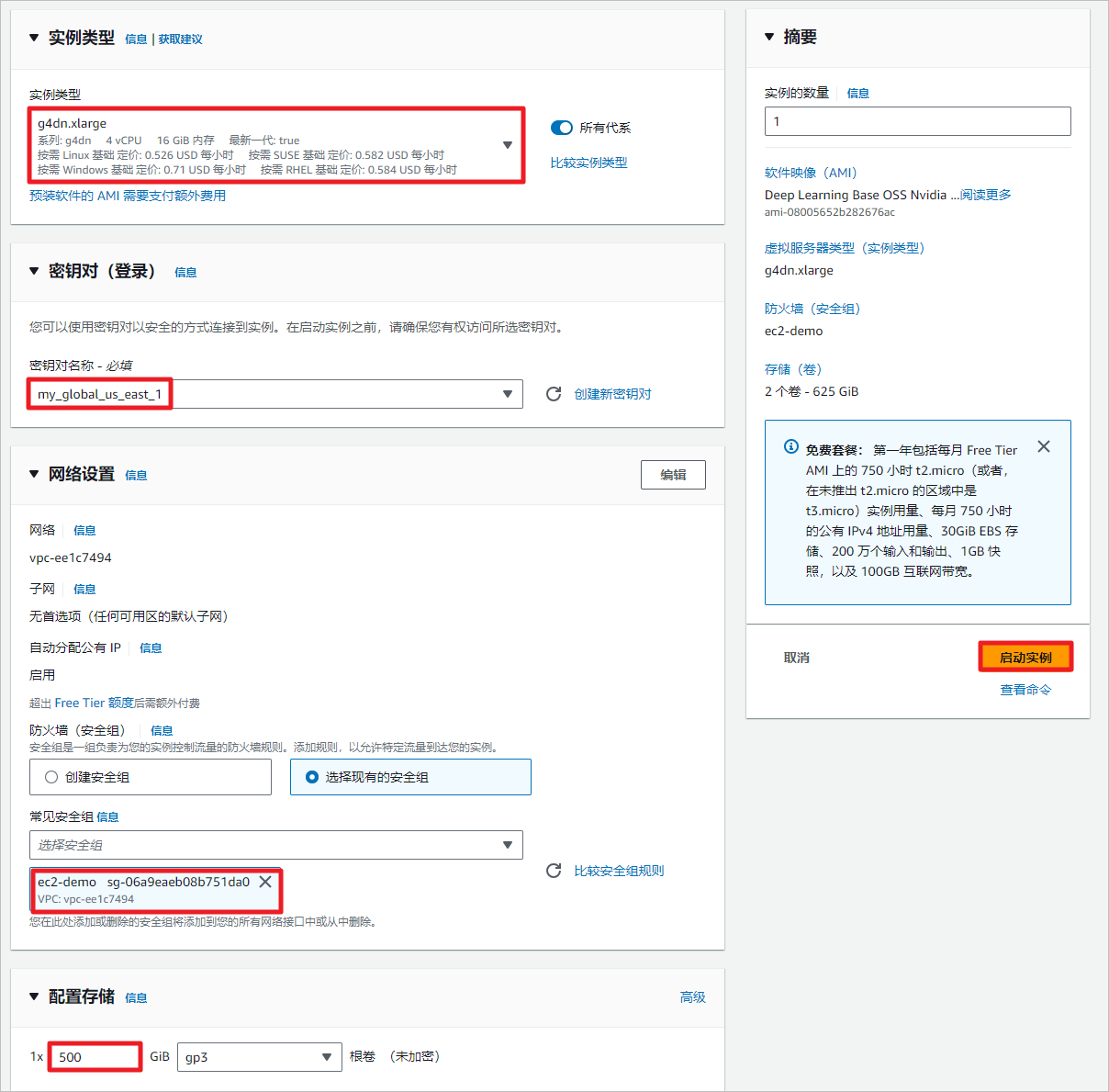
实例已经预装了英伟达驱动,启动之后通过nvidia-smi命令查看一下GPU信息。
root@ip-172-31-83-158:~# nvidia-smi
Fri Jul 5 03:34:19 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 33C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
进入Qwen2-0.5B-Instruct页面https://huggingface.co/Qwen/Qwen2-0.5B-Instruct ,拷贝模型链接 [5]。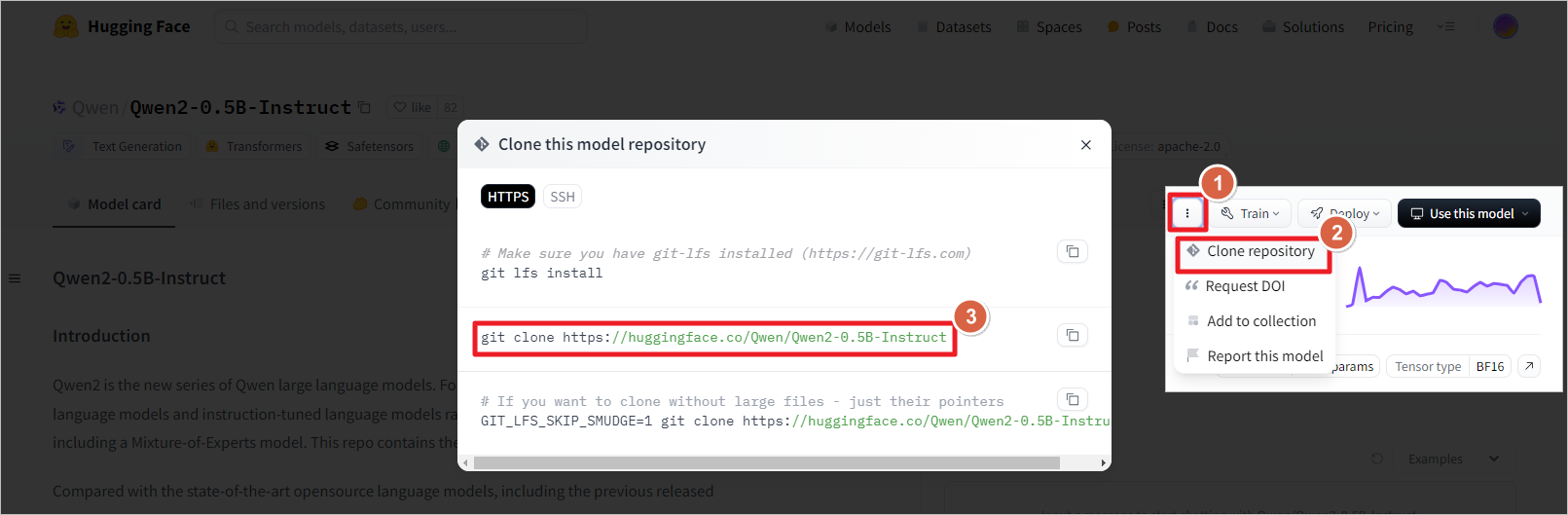
要下载模型文件,需要先安装git-lfs,否则不会下载项目中的大型文件。
Git LFS(Large File Storage)是一个Git扩展工具,用于高效管理大文件。它通过将大文件存储在单独的LFS存储库中,避免了Git仓库体积过大,提升了项目管理效率。Git LFS特别适用于需要处理大型文件的项目,如音乐、图片、视频等。该工具易于安装和配置,并且在多个平台上有良好的支持。
root@ip-172-31-83-158:~# apt update -y
root@ip-172-31-83-158:~# apt install git-lfs -y
下载模型文件
root@ip-172-31-83-158:~# git clone https://huggingface.co/Qwen/Qwen2-0.5B-Instruct
查看模型文件
root@ip-172-31-83-158:~# cd Qwen2-0.5B-Instruct/
root@ip-172-31-83-158:~/Qwen2-0.5B-Instruct# ll -h
total 954M
drwxr-xr-x 3 root root 4.0K Jul 5 03:36 ./
drwx------ 8 root root 4.0K Jul 5 03:36 ../
drwxr-xr-x 9 root root 4.0K Jul 5 03:36 .git/
-rw-r--r-- 1 root root 1.5K Jul 5 03:36 .gitattributes
-rw-r--r-- 1 root root 12K Jul 5 03:36 LICENSE
-rw-r--r-- 1 root root 3.5K Jul 5 03:36 README.md
-rw-r--r-- 1 root root 659 Jul 5 03:36 config.json
-rw-r--r-- 1 root root 242 Jul 5 03:36 generation_config.json
-rw-r--r-- 1 root root 1.6M Jul 5 03:36 merges.txt
-rw-r--r-- 1 root root 943M Jul 5 03:36 model.safetensors
-rw-r--r-- 1 root root 6.8M Jul 5 03:36 tokenizer.json
-rw-r--r-- 1 root root 1.3K Jul 5 03:36 tokenizer_config.json
-rw-r--r-- 1 root root 2.7M Jul 5 03:36 vocab.json
安装python包依赖,这三个python包都比较大,下载时间较长。
root@ip-172-31-83-158:~# pip install transformers torch accelerate
国内可以指定pip安装源。
pip install transformers torch -i https://pypi.tuna.tsinghua.edu.cn/simple
拷贝官方提供的快速启动脚本,这里我修改模型的路径为绝对路径"/root/Qwen2-0.5B-Instruct",Prompt修改为"你是谁?",增加了打印响应结果。
vim /root/qwen0.5b-demo.py
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"/root/Qwen2-0.5B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
prompt = "你是谁?"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
运行脚本,查看模型返回结果。
root@ip-172-31-83-158:~# python3 qwen0.5b-demo.py
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token.As a consequence, you s `attention_mask` to obtain reliable results.
我是阿里云开发的一款超大规模语言模型,我叫通义千问。
查看GPU消耗。
ubuntu@ip-172-31-83-158:~$ nvidia-smi
Fri Jul 5 03:51:05 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 37C P0 32W / 70W | 1313MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3152 C python3 1308MiB |
+---------------------------------------------------------------------------------------+
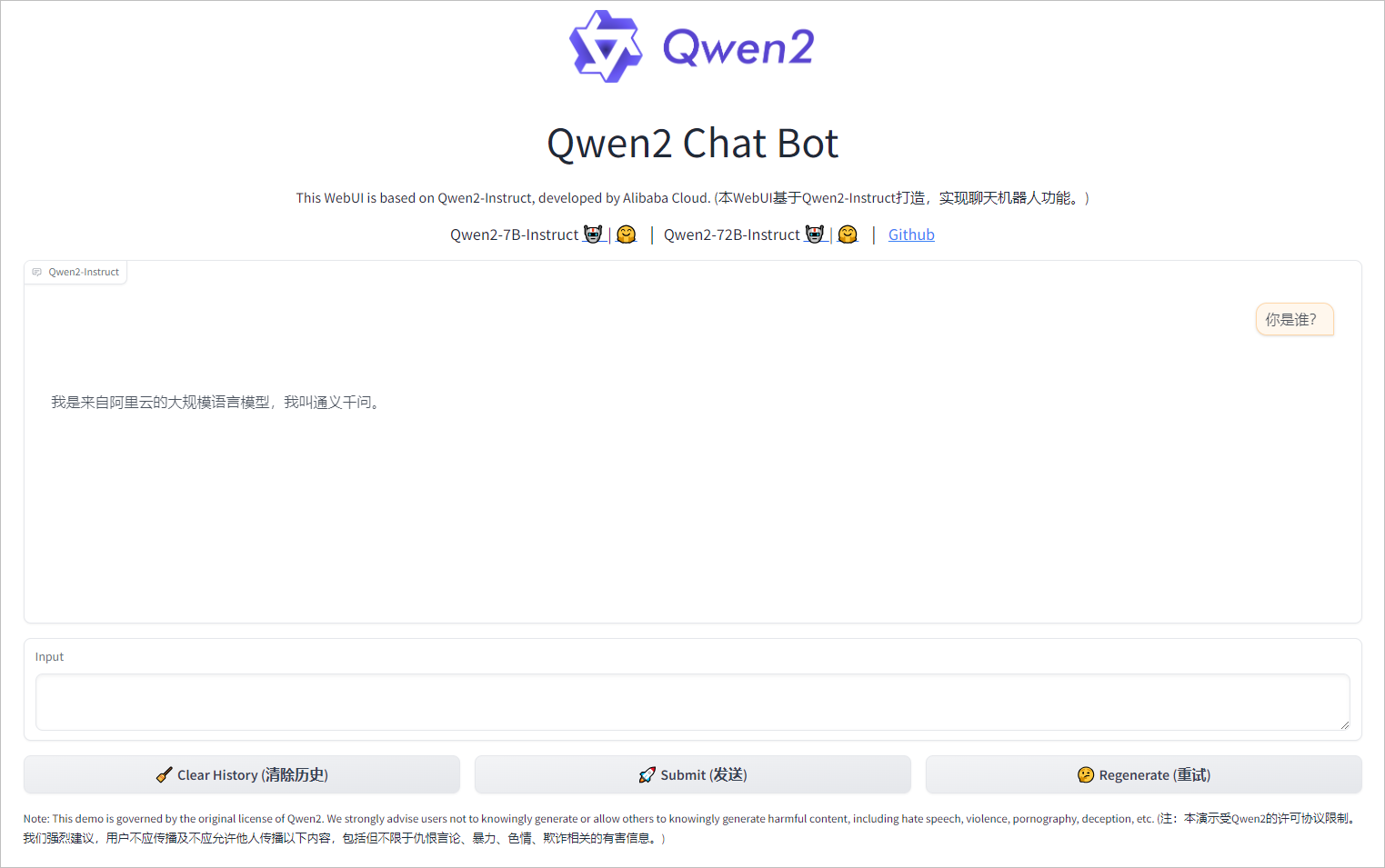
Qwen Gradio 图形化界面
命令行进行对话并不方便,可以使用官方提供的web_demo.py脚本 [6],通过图形化页面进行对话,脚本网址是https://github.com/QwenLM/Qwen2/blob/main/examples/demo/web_demo.py。
安装脚本所需要的依赖,前面已经安装过transformers torch accelerate这三个库了,这里只需要安装gradio即可。
root@ip-172-31-83-158:~# pip install gradio
运行脚本,-- server-name 0.0.0.0允许所有地址进行访问,--checkpoint-path /root/Qwen2-0.5B-Instruct指定模型文件所在目录。
root@ip-172-31-83-158:~# python3 web_demo.py --server-name 0.0.0.0 --checkpoint-path /root/Qwen2-0.5B-Instruct
使用公网地址加上8000端口打开网页查看。
五、文档链接
- [1] 开源大模型排行榜:https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- [2] 大模型聊天竞技场: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
- [3] Qwen 的 Spaces 空间:https://huggingface.co/Qwen
- [4] Qwen2-72B-Instruct Spaces 空间:https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
- [5] Qwen2-0.5B-Instruct 模型下载地址: https://huggingface.co/Qwen/Qwen2-0.5B-Instruct
- [6] Qwen2 网页demo代码 https://github.com/QwenLM/Qwen2/blob/main/examples/demo/web_demo.py