
Ollama 结合 Open-WebUI 本地运行大模型


本文介绍了如何使用 Ollama 在本地运行大型语言模型,以及利用 Open-WebUI 提供的图形化界面与大语言模型进行交互。
一、Ollama 简介
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型(LLM)。它的主要特点和功能如下:
- 简化部署:Ollama 旨在简化在 Docker 容器中部署 LLM 的过程,使得管理和运行这些模型变得更加容易。安装完成后,用户可以通过简单的命令行操作启动和运行大型语言模型。例如,要运行 Gemma 2B 模型,只需执行命令
ollama run gemma:2b。 - 捆绑模型组件:它将模型权重、配置和数据捆绑到一个包中,称为 Modelfile,这有助于优化设置和配置细节,包括 GPU 使用情况。
- 支持多种模型:Ollama 支持多种大型语言模型,如 Llama 2、Code Llama、Mistral、Gemma 等,并允许用户根据特定需求定制和创建自己的模型。
- 跨平台支持:支持 Windows、macOS 和 Linux 平台。安装过程简单,用户只需访问 Ollama 的官方网站下载相应平台的安装包即可。
二、Docker安装 Ollama
选择Deep Learning类型的AMI,这个类型的AMI已经预先安装了英伟达的驱动。
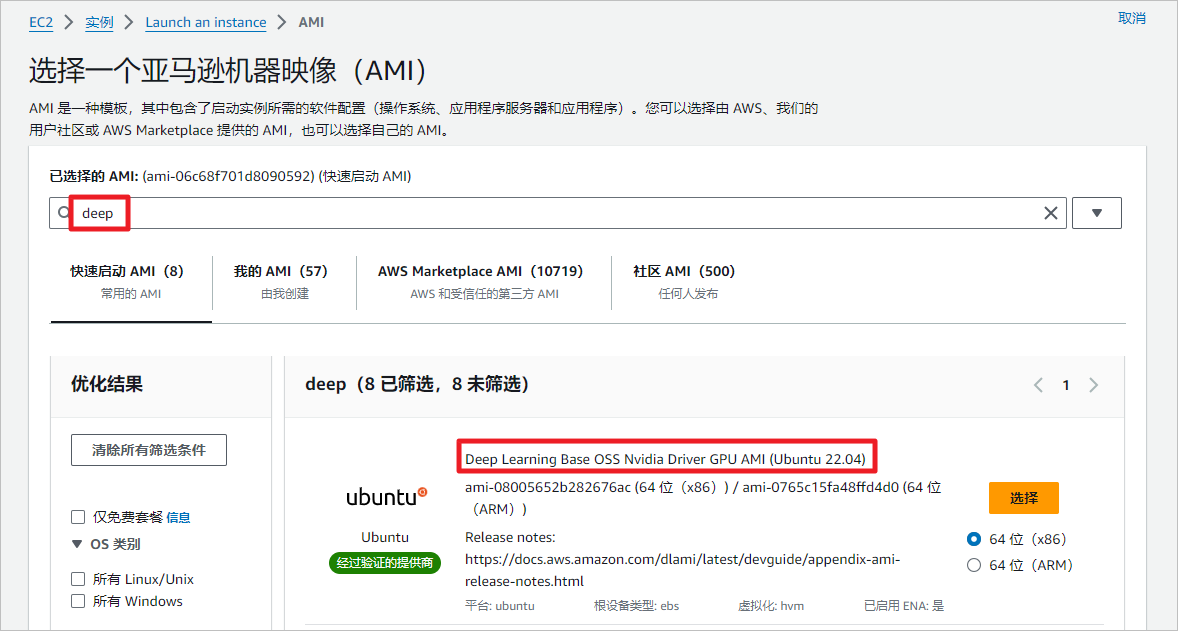
选择g4dn.xlarge类型实例,带有1个NVIDA T4显卡,共有16GB GPU,这是带有英伟达显卡最便宜的实例。这个AMI已经预装了docker包,如果没有安装的Ubuntu系列系统,可以通过下面命令安装。
apt update -y
apt install docker -y
systemctl start docker
拉取ollama docker镜像(依赖网速,2-3分钟左右)
docker pull ollama/ollama
查看镜像文件,镜像大概2GB左右。
~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ollama/ollama latest d5cbea22fd07 30 hours ago 1.98GB
根据Docker Hub ollama主页 https://hub.docker.com/r/ollama/ollama [1],快速启动容器,注意,这里没有添加GPU参数,是通过CPU加载启动的。
~# docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
查看容器状态。
root@ip-172-31-83-158:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e43072764685 ollama/ollama "/bin/ollama serve" 6 seconds ago Up 5 seconds 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama
在docker容器内运行模型(1分钟左右拉起来)。
root@ip-172-31-83-158:~# docker exec -it ollama bash
root@e43072764685:/# ollama run qwen2:0.5b
>>> 你叫什么?
我叫通义千问。
新开一个SSH窗口,在模型回答问题时,查看通过top命令,查看CPU使用率,可以看到CPU已经满负荷运行了,正在使用CPU进行推理。
top - 08:41:19 up 5:14, 4 users, load average: 0.32, 0.25, 0.13
Tasks: 161 total, 3 running, 158 sleeping, 0 stopped, 0 zombie
%Cpu(s): 31.9 us, 0.2 sy, 0.0 ni, 67.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
MiB Mem : 15779.1 total, 1575.5 free, 518.2 used, 13685.4 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 14806.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7080 root 20 0 1067764 442088 344752 R 123.3 2.7 0:17.46 ollama_llama_se
7006 root 20 0 2365904 400032 389632 S 1.0 2.5 0:13.81 ollama
6986 root 20 0 1238716 13636 9856 S 0.7 0.1 0:00.23 containerd-shim
通过ollama list命令,查看下载的所有模型。
root@e43072764685:/# ollama list
NAME ID SIZE MODIFIED
qwen2:0.5b 6f48b936a09f 352 MB About a minute ago
在模型回答问题时,通过nvidia-smi命令查看GPU使用情况,通过CPU进行推理时,看到并没有暂用GPU资源。
root@ip-172-31-83-158:~# nvidia-smi
Fri Jul 5 08:41:38 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 33C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
删除容器。
root@ip-172-31-83-158:~# docker rm -f ollama
ollama
重启启动ollama容器,通过GPU启动。
root@ip-172-31-83-158:~# docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
b094349fc98c8dee31640485ed88ecef38202e33baadcbb9d503ecc1055ac974
Ollama 环境变量
通过下面命令,ollama可以加载环境变量,可以根据实际需求决定是否添加对应的环境变量。
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always -e OLLAMA_KEEP_ALIVE=-1 ollama/ollama
ollama常用环境变量:
- OLLAMA_KEEP_ALIVE=-1,模型加载后,默认的Keepalive是5分钟,修改为-1可以让模型持续启动,OLLAMA_KEEP_ALIVE=60 表示 60 秒,OLLAMA_KEEP_ALIVE=10m 表示10分钟。https://github.com/ollama/ollama/pull/3094
- OLLAMA_ORIGINS=*,跨域访问环境变量,可以用与沉浸式翻译。
Ollama 升级
ollama升级过程参考,停止容器后,重新拉取容器启动即可。
root@ip-172-31-83-158:~# docker exec -it ollama bash
root@3d1be8deba41:/# ollama -v
ollama version is 0.1.40
(base) root@ip-172-31-79-195:~# docker pull ollama/ollama
Using default tag: latest
latest: Pulling from ollama/ollama
7646c8da3324: Pull complete
d1060ab4fb75: Pull complete
e58f7d737fbb: Pull complete
Digest: sha256:4a3c5b5261f325580d7f4f6440e5094d807784f0513439dcabfda9c2bdf4191e
Status: Downloaded newer image for ollama/ollama:latest
docker.io/ollama/ollama:latest
(base) root@ip-172-31-79-195:~# docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 -e OLLAMA_ORIGINS=* --name ollama --restart always ollama/ollama
root@46648320fcd4:/# ollama -v
ollama version is 0.3.7
三、Open-WebUI
OpenWebUI是一个可扩展、功能丰富且用户友好的自托管WebUI,它支持完全离线操作,并兼容Ollama和OpenAI的API。这为用户提供了一个可视化的界面,使得与大型语言模型的交互更加直观和便捷 [3]。
从docker hub拉取open-webui镜像(文件1G左右,看网速,2-3分钟)
docker pull dyrnq/open-webui:main
注意,官方文档是从 GitHub Container Registry (GHCR) 上拉取镜像,而不是从 Docker Hub。官方文档拉取命令如下:
docker pull ghcr.io/open-webui/open-webui:main
查看镜像
root@ip-172-31-83-158:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
dyrnq/open-webui main 8aa8279a3e25 10 hours ago 3.9GB
ollama/ollama latest d5cbea22fd07 30 hours ago 1.98GB
启动docker镜像,映射出来3000端口。
root@ip-172-31-83-158:~# docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always dyrnq/open-webui:main
查看EC2的公网IP地址。
root@ip-172-31-83-158:~# curl ifconfig.me
54.243.6.37
访问Open WebUI。
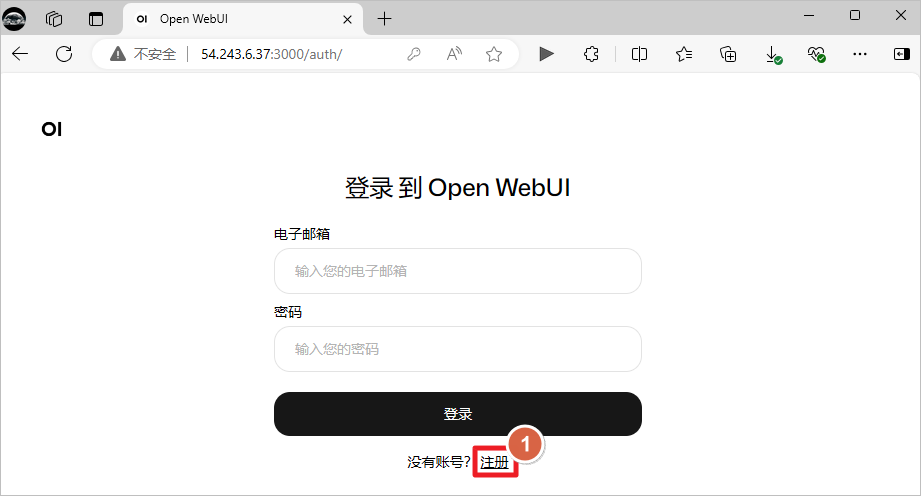
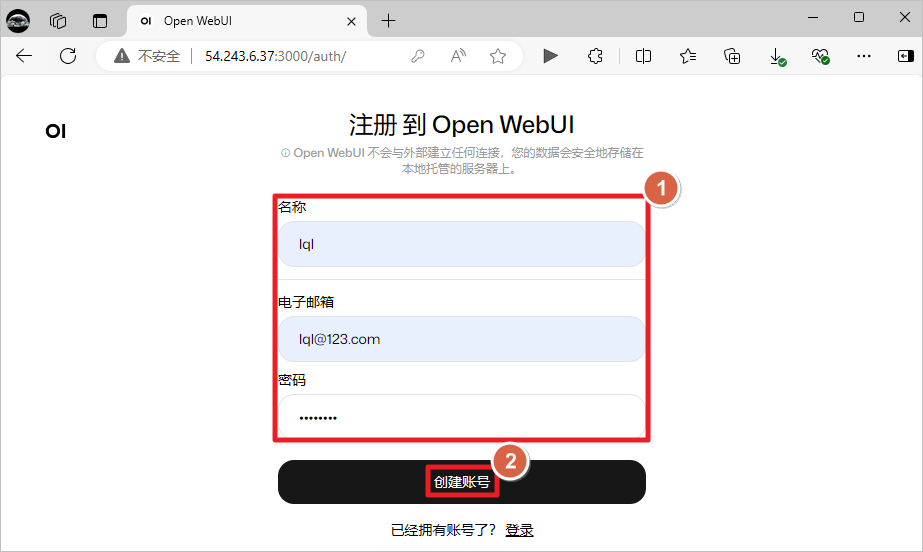
创建账号,这个是本地账号,随便添加账号信息即可。
选择ollama中的模型,聊天测试。
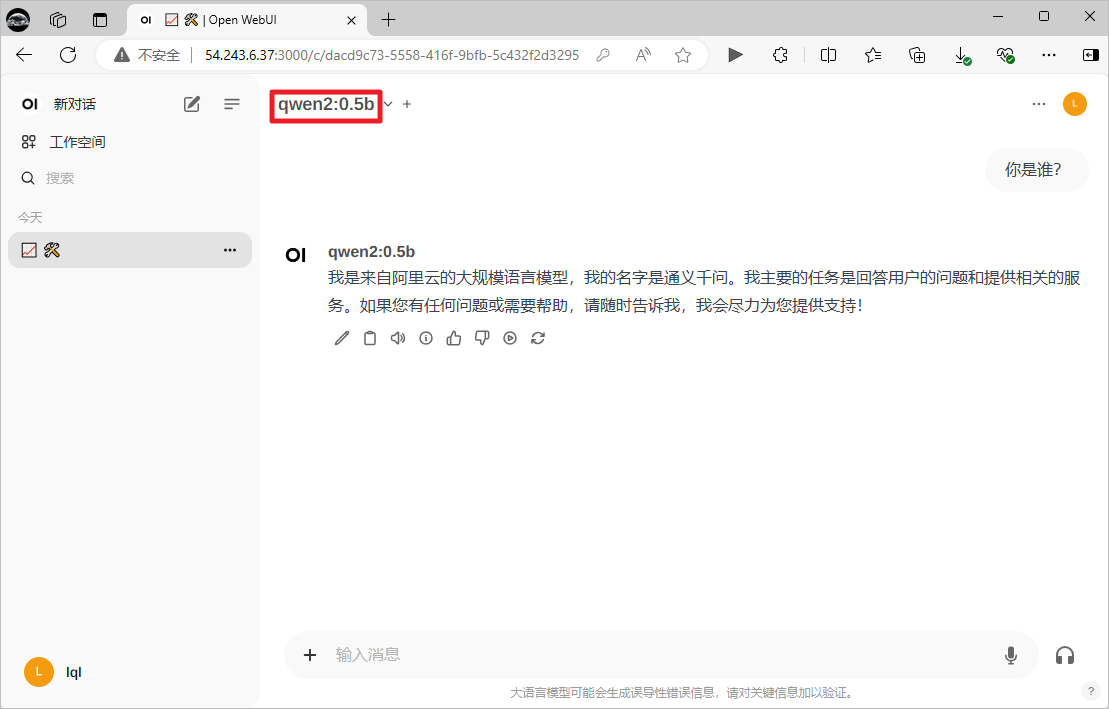
可以直接拉取目前ollama没有的模型。
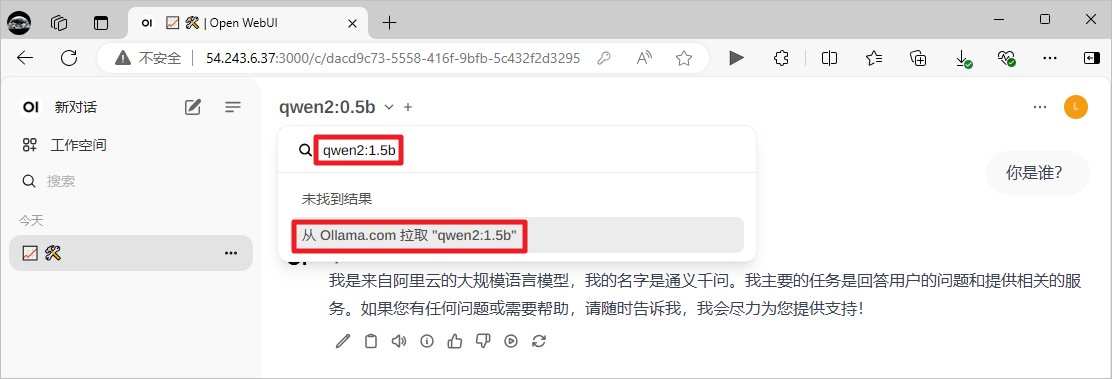
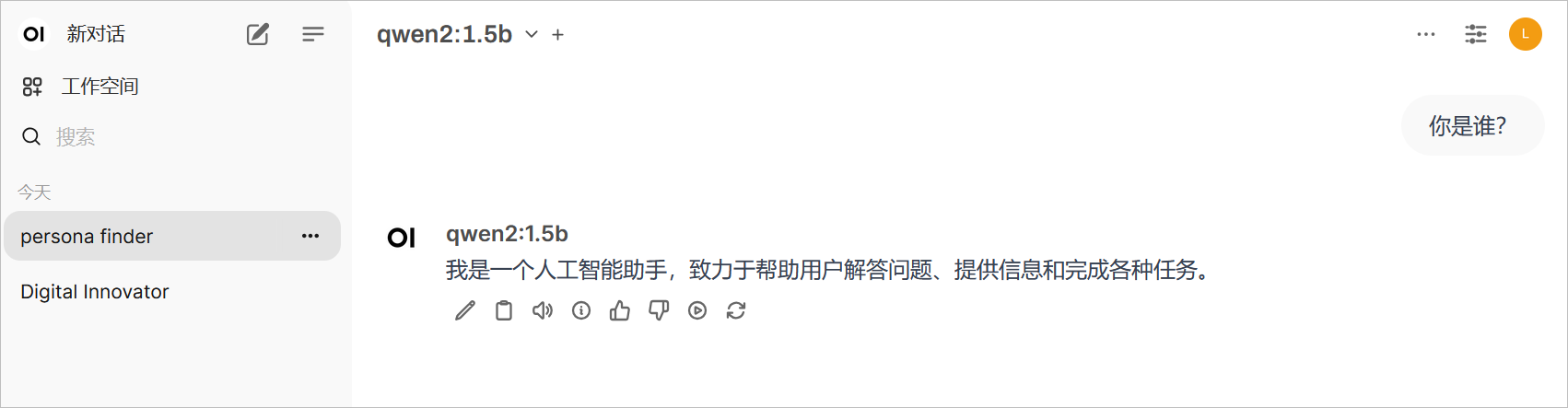
与下载的新模型进行对话。
四、文档链接
- [1] Dockerhub ollama镜像文件:https://hub.docker.com/r/ollama/ollama
- [2] ollama keepalive:https://github.com/ollama/ollama/pull/3094
- [3] Open WebUI Github:https://github.com/open-webui/open-webui