
Python对文本中的特定单词进行逆序替换


需求描述
前端时间做了一个Python的小练习题,这个问题初看简单,做下来发现有不少以前没有了解的知识点,这里记录一下解决的过程。
需求:在文本里面任意给定一个单词,将这个单词逆序之后替换原来位置的单词,返回替换后的文本。
这里随意写了一段文本,需要进行逆序替换的关键字是long
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
替换后的效果如下:
gnol The time that my journey takes is gnol and the way of it gnol.I came out on loanglong
the chariot of the first gleam gnol, of light, gnol many a star and planet gnol
推荐大家先自己做一下这个题,直接看答案就失去了很多乐趣,实在做不出来再慢慢看这个答案。
.
.
.
做
题
中
.
.
.
需求分析
这个需求大致看来就2个步骤:1、将单词进行逆序;2、用逆序后的单词替换原来的单词。
将单词进行逆序方法还是比较多的,逆序之后进行替换这个需求应该很快能想到正则表达式来做替换。总体思路没有问题,下面开干。
解决步骤
逆序单词
首先想到的是reverse方法,将单词转换为一个列表,然后用reverse方法逆序列表,最后用join方法将列表里面的单词组合起来。
import re
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
keyword = 'long'
reverse_key = list(keyword)
reverse_key.reverse()
new_k1 = ''.join(reverse_key)
print(new_k1)
输入结果如下:
gnol
上面的结果确实满足了要求,但是解决的不够优雅,这里推荐用更加简洁的一种方法,这是python的slice notation的特殊用法,格式为a[i:j:s],这里i和j都缺省了相当于复制了一份keyword,s 表示步进,默认为1,当为负数时表示从右往左取,所以keyword[::-1]即为逆序复制。
import re
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
keyword = 'long'
new_k1 = keyword[::-1]
print(new_k1)
参考链接:https://www.cnblogs.com/mxh1099/p/5804064.html
a = [0,1,2,3,4,5,6,7,8,9]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
b = a[1:3] 那么,b的内容是 [1,2]
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
当i,j都缺省时,a[:]就相当于完整复制一份a了b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1.
所以a[i:j:1]相当于a[i:j]
当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。
替换单词
replace方法
要做正则替换刚开始我想到了replace方法,但是使用这个方法会误伤到包含关键字的单词,例如下面我乱构造的「单词」loanglong内部的long也被做了替换,这显然不是想要的结果。我只想要对特定
的单词进行替换,不是只要包含这几个字母都做替换。这里f'{new_k1}'可以使用f-string导入新的字符串。
inputs = "hello 11 word 11" 想11变成22
replacestr = inputs.replace("11","22")
import re
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
keyword = 'long'
new_k1 = keyword[::-1]
new_str1 = str1.replace('long', f'{new_k1}')
print(new_str1)
gnol The time that my journey takes is gnol and the way of it gnol.I came out on loanggnol
the chariot of the first gleam gnol, of light, gnol many a star and planet gnol
re.sub方法
replace无法解决这个问题,需要re.sub这个方法来解决问题了,这个函数就是主要用来替换字符串中的匹配项。函数有5个参数,前面3个参数是必选项。
re.sub(pattern, repl, string, count=0, flags=0)
pattern:表示正则中要匹配的字符串;repl:表示想要替换的字符串,既匹配出来的pattern替换为repl,这里repl可以是个函数;string:表示要被查找的原始字符串;count:表示要替换的最大次数,默认为0,表示所有匹配的都会被替换,是可选参数;flags:表示编译时用的匹配模式,例如互联大小写、多行模式等,默认为0;
下面用re.sub()方法先试一下,可以看到还是出现一样的问题,我乱构造的「单词」loanglong内部的long也被做了替换。问题出现在匹配不精确,这里我只想要匹配单词long,但是里面包含这个
关键词的不想被匹配到。
import re
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
keyword = 'long'
new_k1 = keyword[::-1]
new_str1 = re.sub(fr'{keyword}', fr'{new_k1}', str1)
print(new_str1)
gnol The time that my journey takes is gnol and the way of it gnol.I came out on loanggnol
the chariot of the first gleam gnol, of light, gnol many a star and planet gnol
零宽断言
这个卡了我特别长时间,因为我不知道”零宽断言“这个「高级货」技术...
这个技术涉及到比较多绕口的名词,先来看下不用这个技术会遇到什么问题。即pattern参数匹配的关键字都会被替换,这里希望描述一下单词的前后是什么内容,但是并不希望这种描述本身也被匹配进去。
所以零宽断言的作用是并不真正匹配字符串,而仅仅是匹配对应的位置,断言本身不会被匹配,因为匹配的宽度为零,所以叫零宽。断言可以理解为判断的意思,正则表达式里面有很多断言,例
如^匹配字符串的开头,$匹配字符串的末尾,\b匹配单词的边界等。
(?<=exp1)(?<!exp2)string(?=exp3)(?!exp4)

?<=代表正回顾后发断言,它断言自身出现的位置的前面可以匹配exp1表达式。例如:(?<=\d)a,返回匹配字符串中以数字为开头的a字符。?=代表正预测先行断言,表示自身出现的位置的后面可以匹配exp3表达式。例如:a(?=\d),返回匹配字符串中以数字为结尾的a字符。?<!代表负回顾后发断言,它断言自身出现的位置的前面不可以匹配exp2的表达式。例如:a(?!\d),返回不匹配字符串中以数字开头的a字符。?!代表负预测先行断言,它断言自身出现的位置的后面不可以匹配exp4表达式。例如:a(?!\d),返回不匹配字符串中以数字结尾的a字符。
上面的概念第一次接触会有点绕,总的来说就是你想描述string这个单词前面一定具备某个特征、后面一定具体某个特征、前面一定没有这个特征、后面一定没有这个特征,一共就是这4种情况。
回到上面的需求,我想要匹配出单独的一个单词long,这个关键词前后有字母的不会被匹配。所以需要匹配出一个单词的边界,就是\b。
\b与\B
这里简单描述\b的作用,它用来匹配一个「单词」的边界,边界近似于\w即([0-9a-zA-Z_])。
例如下面的字符串abc!123_,这里认为abc和123_都是一个「单词」,那么它们的前后就是边界。\B取\b的相反即可,
import re
str1 = 'abc!123_'
result1 = re.findall(r'\b', str1)
result2 = re.findall(r'\B', str1)
print(result1)
print(result2)
['', '', '', '']
['', '', '', '', '']
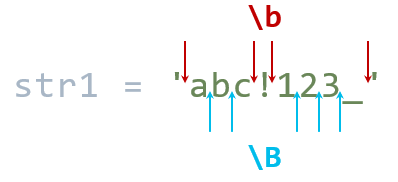
最终的代码如下:
import re
str1 = '''long The time that my journey takes is long and the way of it long.I came out on loanglong
the chariot of the first gleam long, of light, long many a star and planet long'''
keyword = 'long'
new_k1 = keyword[::-1]
new_str1 = re.sub(fr'(?<=\b){keyword}(?=\b)', fr'{new_k1}', str1)
print(new_str1)
gnol The time that my journey takes is gnol and the way of it gnol.I came out on loanglong
the chariot of the first gleam gnol, of light, gnol many a star and planet gnol
参考资料
- Python3 re模块:https://docs.python.org/3/library/re.html
- 正则表达式sub:https://www.jb51.net/article/170226.htm
- 正则表达式的\b与\B:https://www.jb51.net/article/138235.htm
- 零宽断言:https://www.shuzhiduo.com/A/QW5Y2nZBdm/