
Xinference 本地运行大模型


本文介绍了如何使用 Docker 部署 Xinference 推理框架,并演示了如何启动和运行多种大模型,包括大语言模型、图像生成模型和多模态模型。还讲解了嵌入和重排模型的启动方法,为后续 Dify 调用嵌入和重排模型做为铺垫。
一、Xinference 简介
Xorbits Inference (Xinference) 是一个开源的分布式推理框架,专为大规模模型推理任务设计。它支持大语言模型(LLM)、多模态模型、语音识别模型等多种模型的推理。以下是 Xinference 的主要特点 [1]:
- 模型一键部署:极大简化了大语言模型、多模态模型和语音识别模型的部署过程。
- 内置前沿模型:支持一键下载并部署大量前沿开源模型,如
Qwen2、chatglm2、等。 - 异构硬件支持:可以利用 CPU 和 GPU 进行推理,提升集群吞吐量和降低延迟。
- 灵活的 API:提供包括 RPC 和 RESTful API 在内的多种接口,兼容 OpenAI 协议,方便与现有系统集成。
- 分布式架构:支持跨设备和跨服务器的分布式部署,允许高并发推理,并简化扩容和缩容操作。
- 第三方集成:与 LangChain 等流行库无缝对接,快速构建基于 AI 的应用程序。
二、Xinference Docker 部署
docker镜像文件非常大,拉取文件需要耗费很长时间。
docker pull xprobe/xinference
查看xinference docker镜像文件,目前大小为17.7GB。
root@ip-172-31-83-158:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
xprobe/xinference latest 96b2be814b0f 2 days ago 17.6GB
创建一个目录,用与存放xinference缓存文件和日志文件。
mkdir -p /xinference/data
启动容器。默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
- XINFERENCE_MODEL_SRC:配置模型下载仓库。默认下载源是 “huggingface”,也可以设置为 “modelscope” 作为下载源。
- XINFERENCE_HOME:Xinference 默认使用
<HOME>/.xinference作为默认目录来存储模型以及日志等必要的文件。其中<HOME>是当前用户的主目录。可以通过配置这个环境变量来修改默认目录。
docker run -d \
--name xinference \
-v /xinference/data/.xinference:/root/.xinference \
-v /xinference/data/.cache/huggingface:/root/.cache/huggingface \
-v /xinference/data/.cache/modelscope:/root/.cache/modelscope \
-v /xinference/log:/workspace/xinference/logs \
-e XINFERENCE_HOME=/xinference \
-p 9997:9997 \
--gpus all \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0 --log-level debug
三、Xinference 本地运行大模型
容器启动后,访问公网地址加上9997端口,启动qwen2-instruct模型。
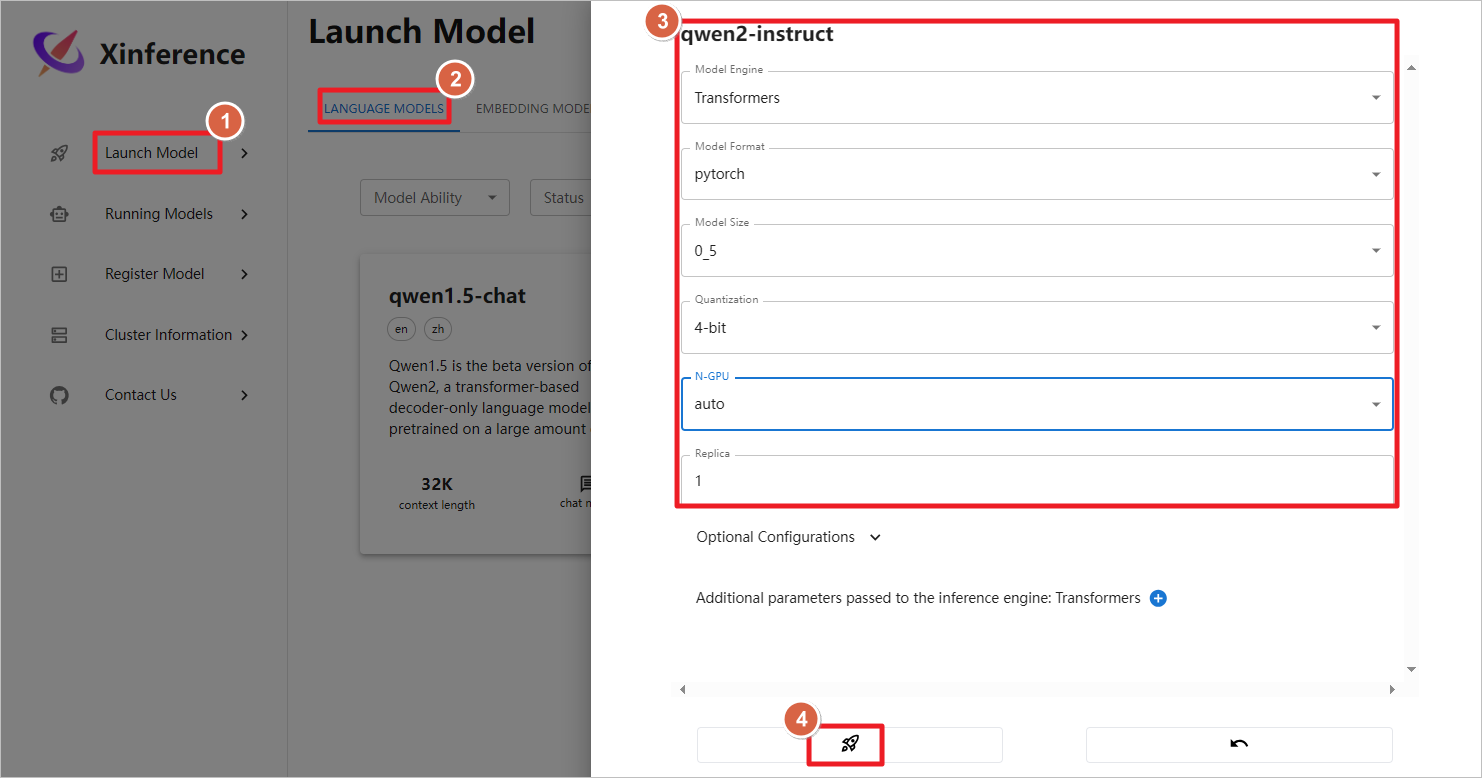
使用Xinference自带的图形化聊天界面。
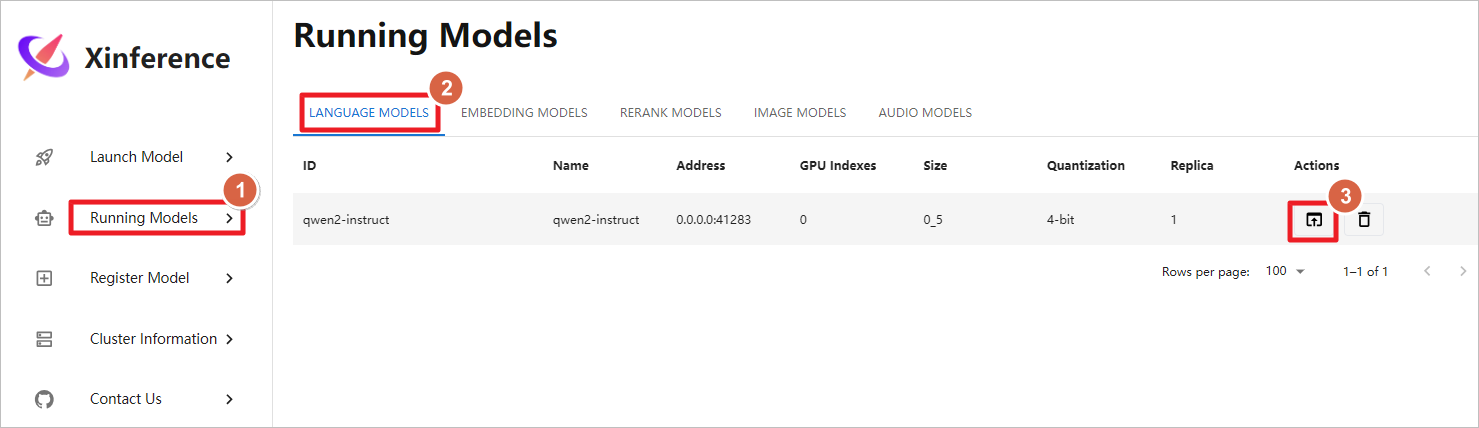
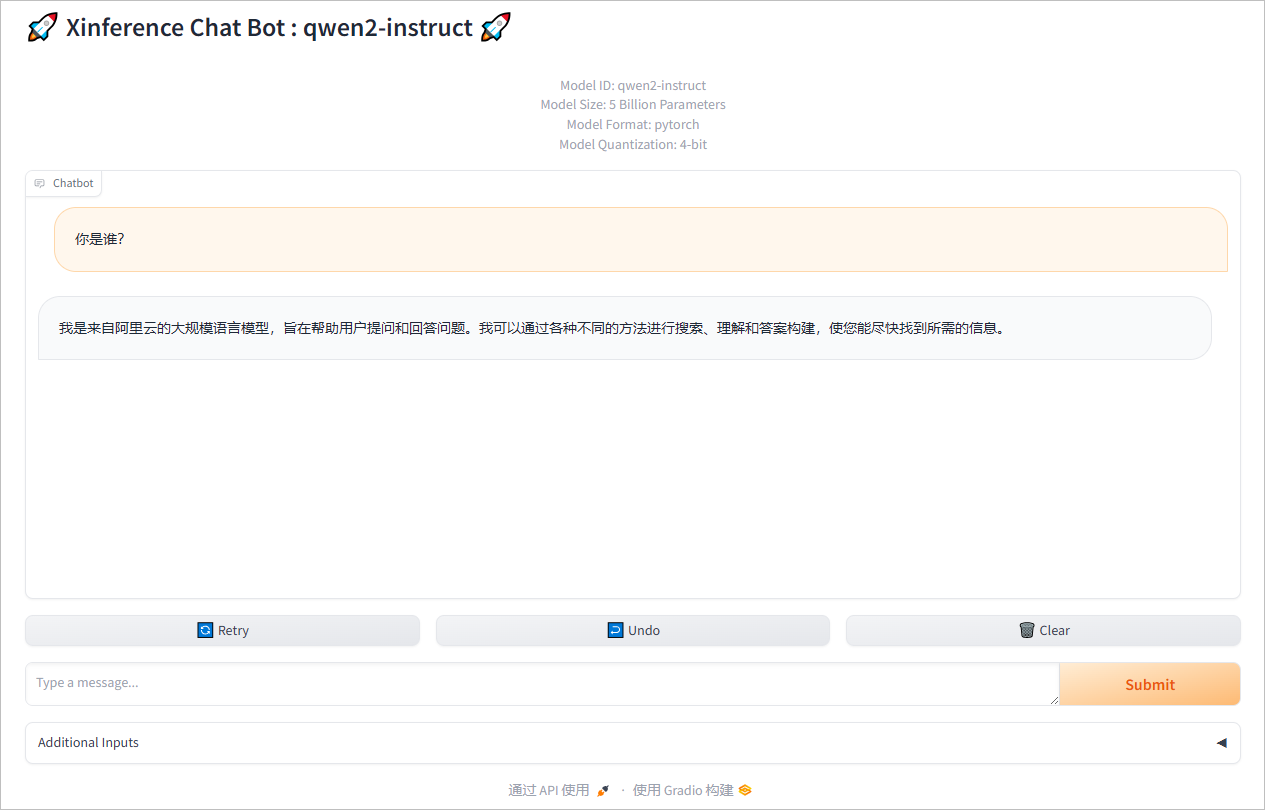
聊天测试。
测试图片生成模型,启动sd-trubo图片生成模型,模型下载和启动的时间较长,需要多等待一会,运行大概需要12G GPU。
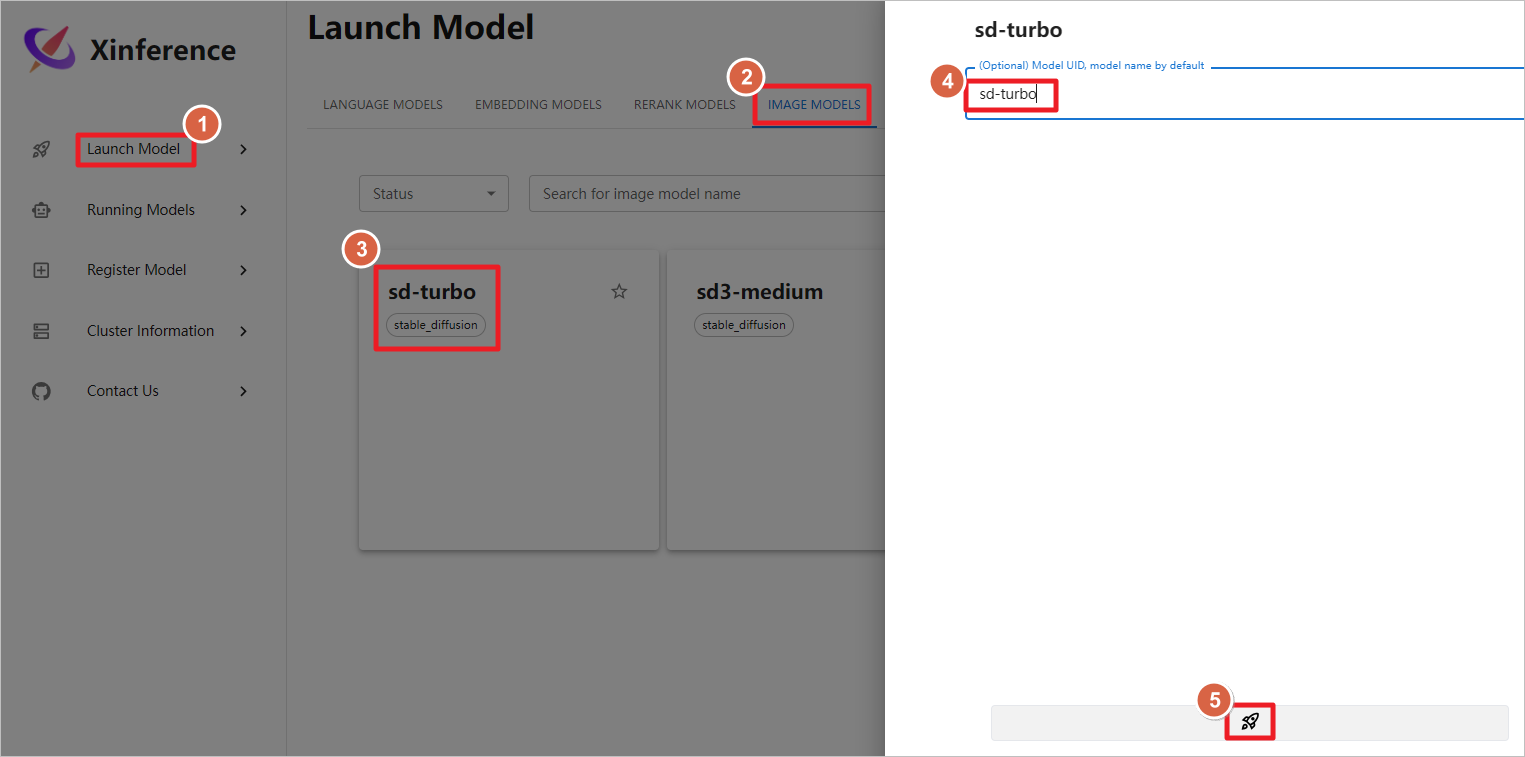
启动图形化聊天界面。
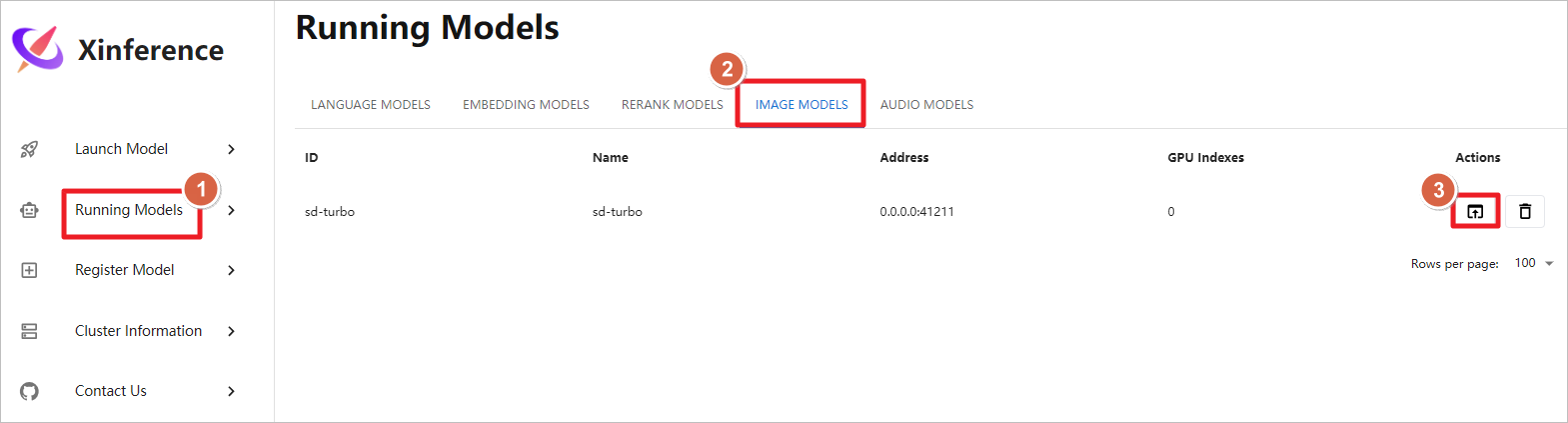
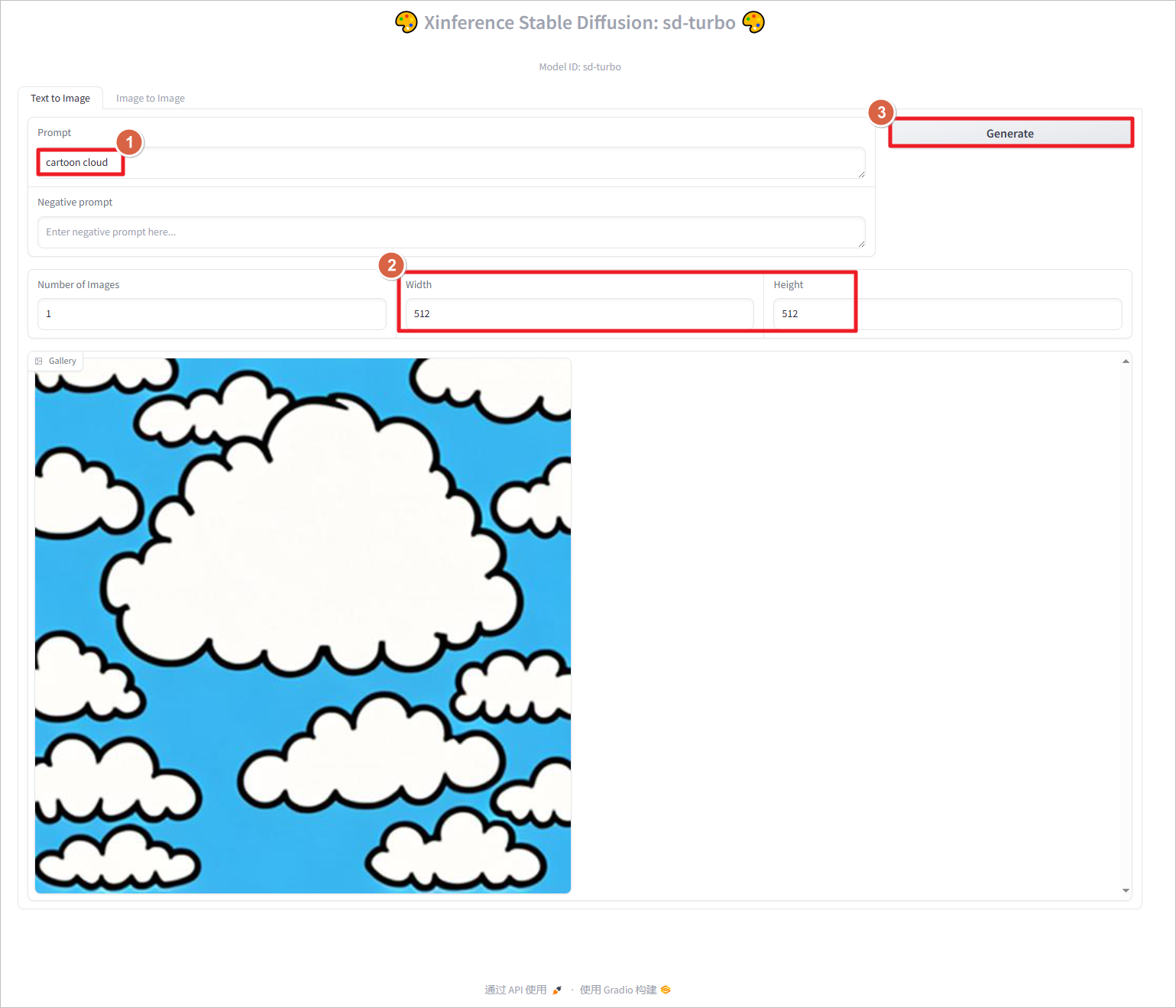
使用提示词cartoon cloud生成图片,设置分辨率为512*512,点击Generate生成图片。图片像素设置的越大,生成的时间越长,占用的GPU越多,设置1024 * 1024像素,大致需要占用6G GPU。
Xinference目前无法同时运行多个大模型,在运行新的模型之前,需要停止之前的模型。
测试多模态模型,启动qwen-vl-chat视觉聊天模型,模型下载和启动也需要较长时间,模型需要20G GPU才能运行,所以至少需要g5.xlarge(24G GPU)才能运行,g4dn.xlarge(16G GPU)无法运行。
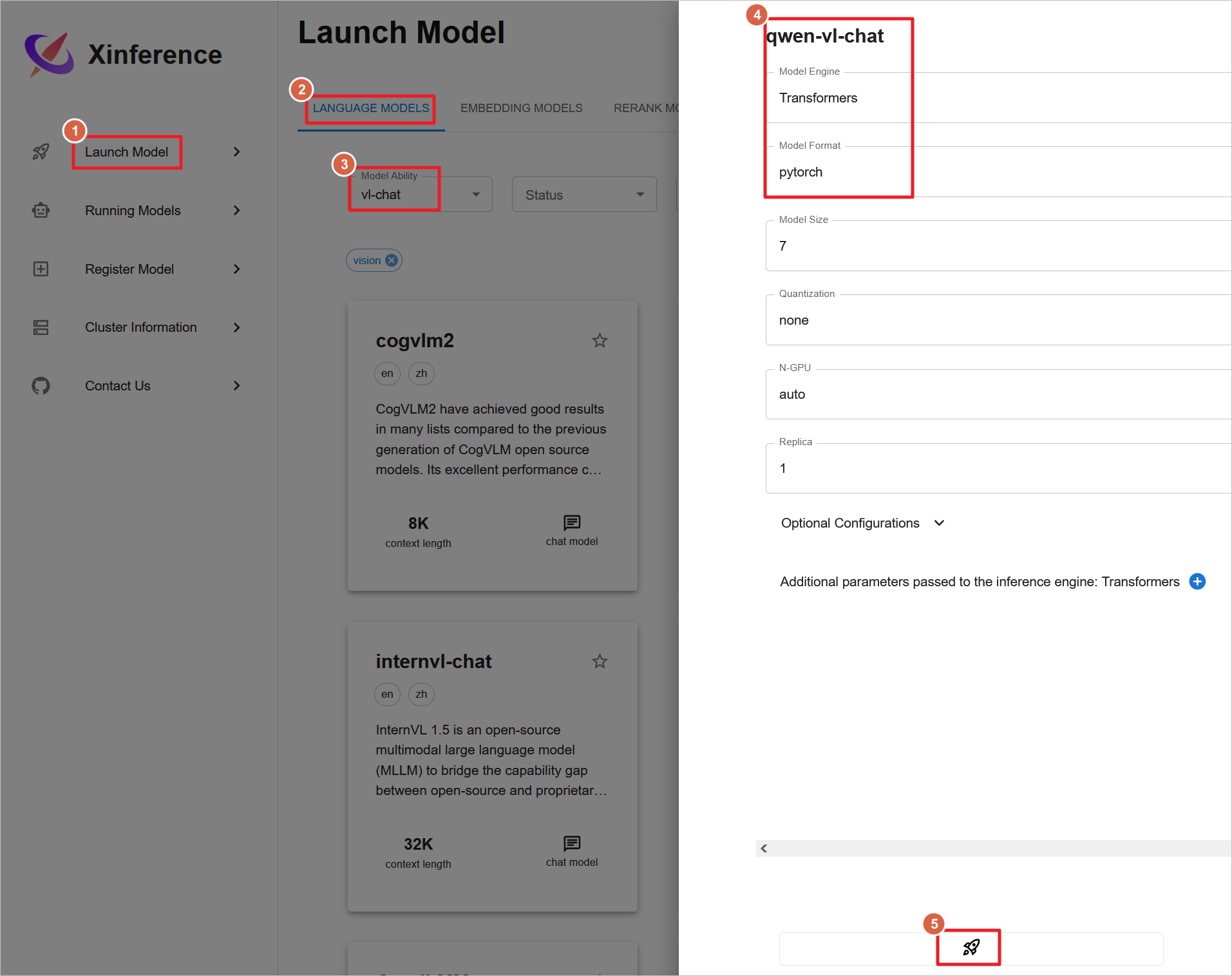
上传图片聊天测试。

四、Xinference 启动嵌入和重排模型
Xinference只能同时启动一个语音模型、图片模型、语音模型,但是可以同时启动多个嵌入模型、重排模型。
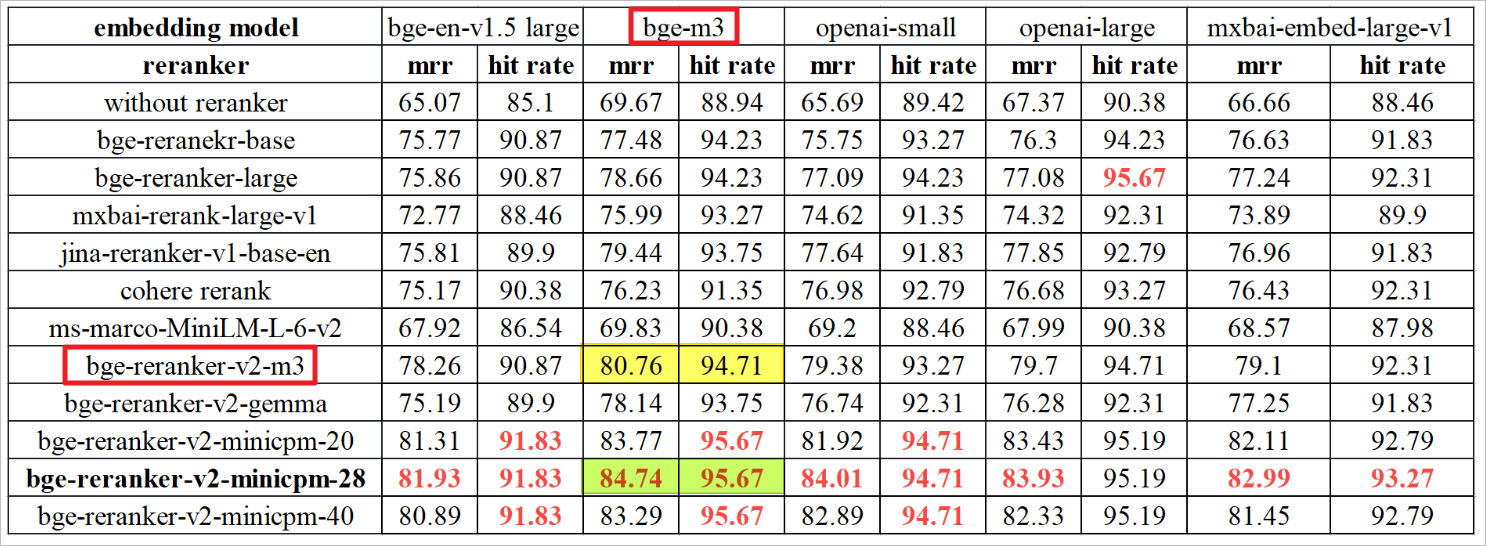
这里使用的嵌入(embedding)模型是bge-m3,重排(reranker)模型是bge-reranker-v2-m3。
启动bge-m3嵌入模型,ollama后续可以调用这个模型。
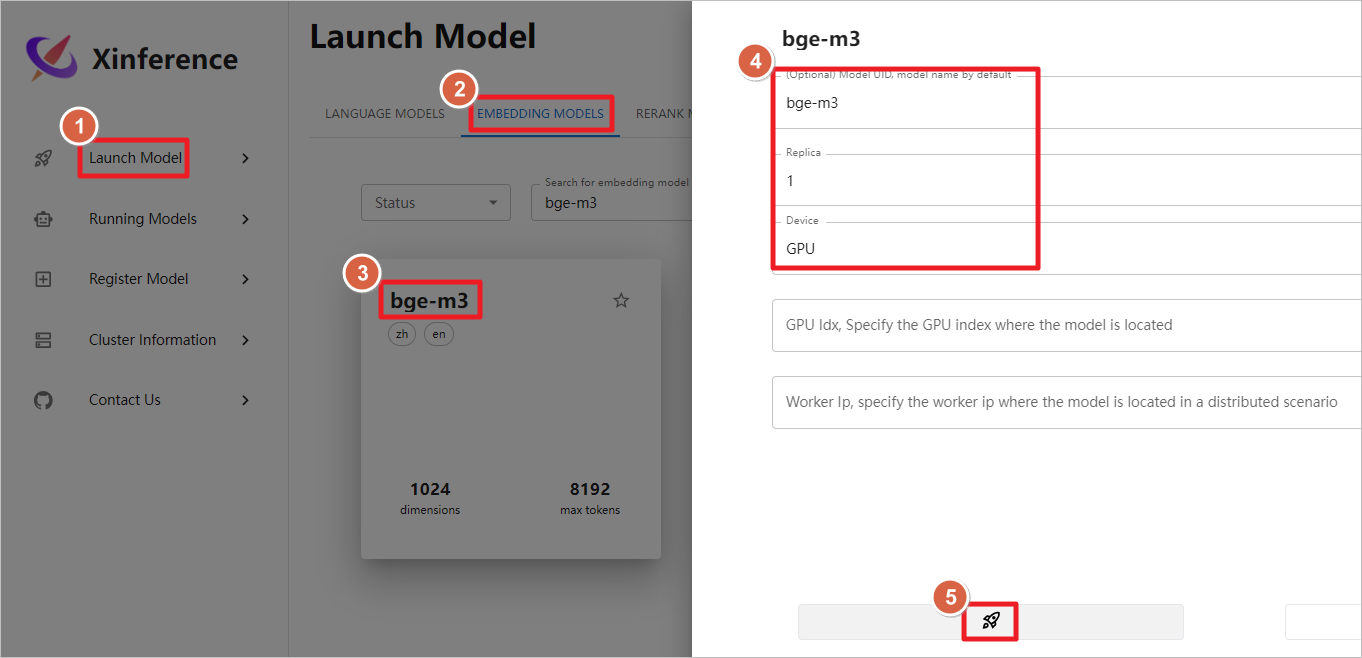
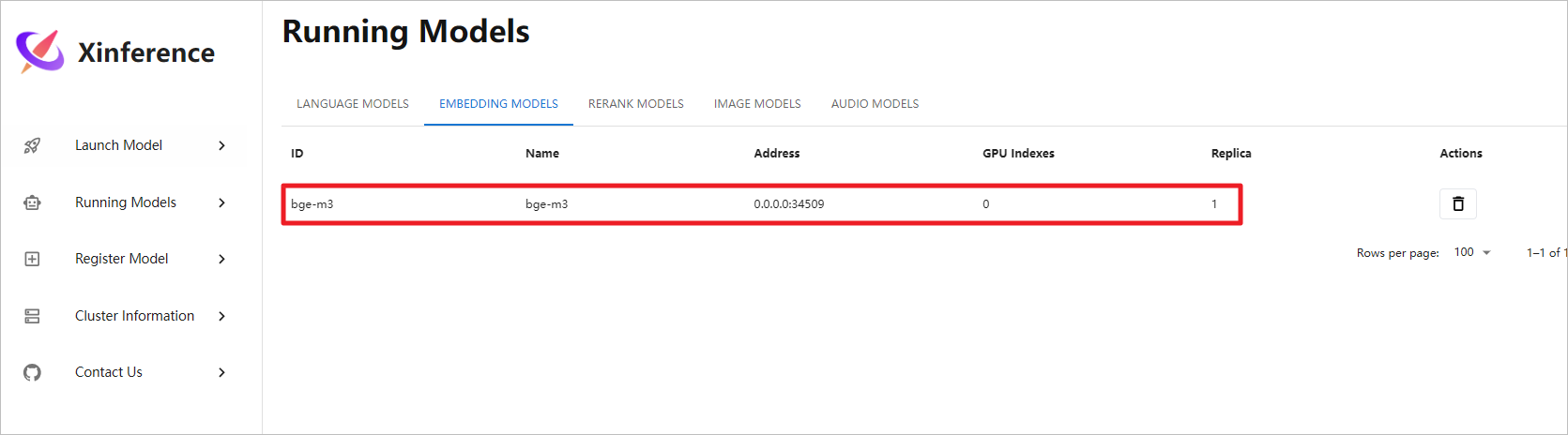
模型正常启动,后续Dify可以调用此嵌入模型。
启动bge-reranker-v2-m3重排模型,ollama 后续可以调用这个模型。
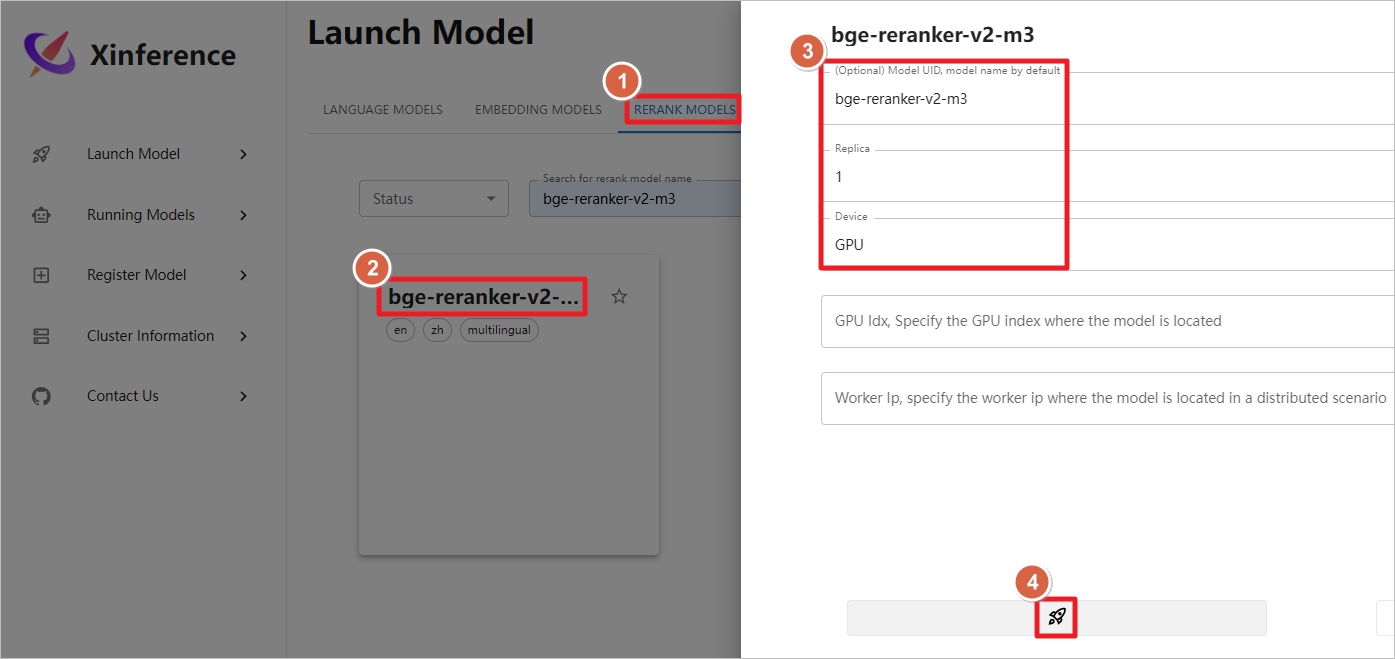
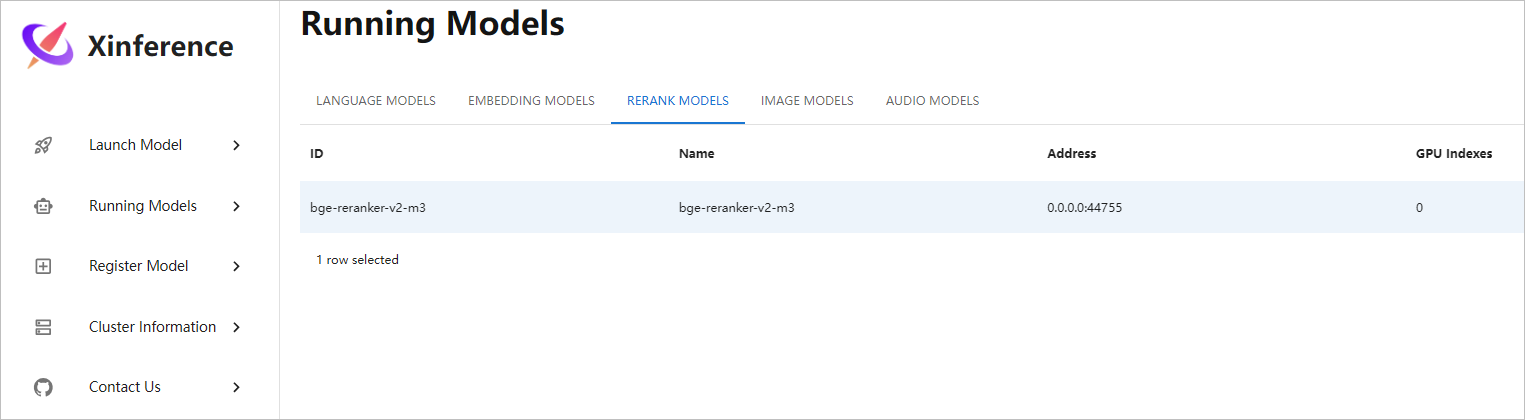
模型正常启动,后续Dify可以调用此重排模型。
五、文档链接
- [1] Xinference Github主页:https://github.com/xorbitsai/inference/blob/main/README_zh_CN.md
- [2] Xinference 环境变量:https://inference.readthedocs.io/zh-cn/latest/getting_started/environments.html
- [3] Xinference Docker安装文档:https://inference.readthedocs.io/zh-cn/latest/getting_started/using_docker_image.html
- [4] 嵌入模型bge-m3:https://huggingface.co/BAAI/bge-m3
- [5] 重排模型bge-reranker-v2-m3:https://huggingface.co/BAAI/bge-reranker-v2-m3